A Shared Language for AI Diffusion

There is a working AI system in Maharashtra that advises farmers on crop disease, pest management, and weather stress in Marathi, through a voice call on a basic phone. It was built by the state agriculture department working with thirty partner organisations over nine months.
Those nine months were not mostly spent building the AI. They were spent on everything the AI required to actually work: data pipelines, governance structures, dialect calibration, frontline worker training, and accountability frameworks that made the information reliable. Over 3 million farmers now use it.
When Ethiopia's Agricultural Transformation Institute built a comparable system, it took only three months. When Amul deployed Sarlaben to serve 3.6 million dairy farmers, it took just three weeks. The technology did not improve that dramatically between deployments. What changed was how much of Maharashtra's hard-won knowledge was available to the teams that came after.

That compression, from nine months to three months to three weeks, is what the 100 Diffusion Pathways initiative exists to produce, systematically, across agriculture, health, education, and livelihoods.
For it to work, the field needs a shared vocabulary. This is what the founding organisations have established as the common framework.
What is AI diffusion?
Diffusion is the process by which AI capability spreads from the institutions that build it to the far larger number of institutions that need it to serve people.
It is distinct from invention. Releasing a model is not diffusion. It is distinct from a single deployment. One government department deploying one system is not diffusion. Diffusion is what happens when that capability spreads reliably and repeatedly across many institutions, each one going faster and cheaper than the last because the knowledge from previous deployments was captured and transferred rather than locked away.
The Carnegie India Use Case Adoption Framework examined hundreds of AI deployments across sectors and found a consistent pattern: technology accounts for roughly 30% of what it takes to reach scale. The other 70% is data readiness, language support, workforce adaptation, accountability structures, and institutional alignment.
This 70% is learnable, only if it is documented in a form that transfers. Diffusion is the system that makes that transfer happen.
What is a use case?
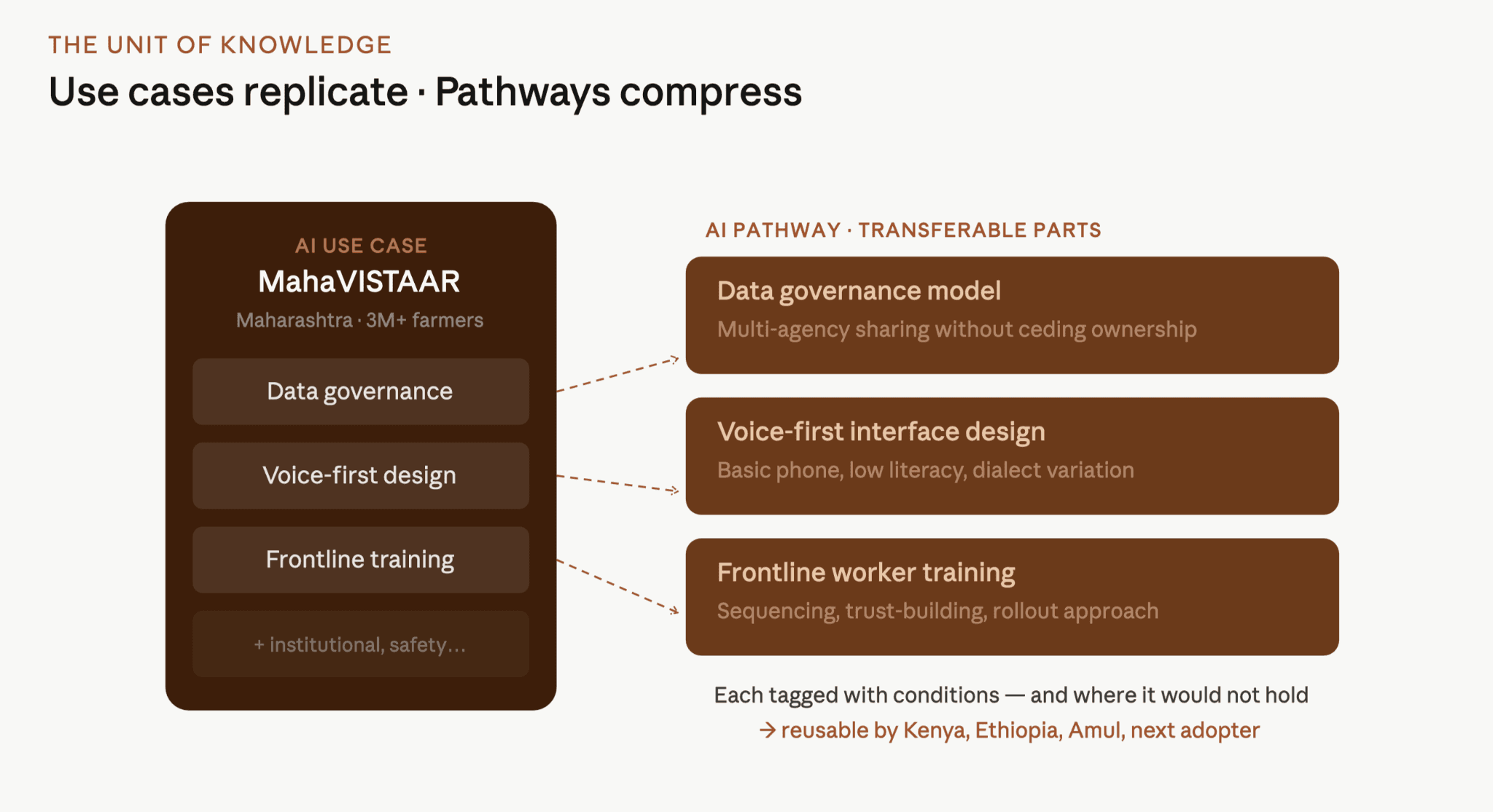
A use case is a specific AI application, built by a specific institution, to serve a specific population. For example, MahaVISTAAR is a use case: the Government of Maharashtra deployed an AI advisory system for farmers, built on Maharashtra's agricultural data infrastructure, calibrated for Marathi dialects, governed by agreements between the agriculture department and its research partners. Every element is particular to that context.
An institution that wants to build something similar in a comparable context can study MahaVISTAAR and replicate it. Most institutions are not in that situation. A health department in Kenya building a community health worker advisory tool operates in a different sector, language environment, regulatory context, and data landscape. It cannot copy MahaVISTAAR.
It can, however, use what MahaVISTAAR learned: how to structure data governance when multiple agencies need to share data without ceding ownership; how to build trust with frontline workers who have never used an AI advisory tool; how to design for voice-first interfaces on basic phones. Those decisions are not specific to Maharashtra or to agriculture. A diffusion pathway is precisely what carries them from one deployment to the next.
What is a diffusion pathway?
A diffusion pathway is the transferable decisions and learnings drawn out of a deployment, documented in a form the next deployer can use. The use case is the whole. The pathway is the parts made reusable.
A pathway has two components:
The first is a deployment playbook: the institutional and operational decisions that determined whether the system worked. Who needed to be in the room before procurement could proceed. How the training programme for frontline staff was sequenced. What governance arrangement made the data-sharing agreement possible.
The second is a reusable toolkit: technical components, data pipeline templates, safety guardrails, and evaluation benchmarks that another team can use directly.
What makes a pathway genuinely useful rather than just descriptive is that every element is tagged with the conditions it depended on, including where it would not hold. The data governance model that worked for MahaVISTAAR depended on an existing relationship between the agriculture department and ICAR. Without that relationship, the same model fails. An institution that knows this before it starts can design around it. An institution that discovers it six months in has lost six months.
A pathway is written from the next adopter's perspective, not the original builder's. It is not a record of what happened. It is an answer to the question the next deployment officer is actually asking: given my context, what do I need to decide, and what has already been learned about how to decide it well.
A use case shows you what is possible. A pathway shows you how to get there. But between those two points, every deployment runs into the same category of obstacles.
What are deployment gaps?
Deployment gaps are the specific blockers that stand between an institution and a working AI system. They are rarely technical. The data exists but is not structured in a way the model can use. The language support covers the national language but not the dialect the target population actually speaks. The governance framework was designed for software procurement, not AI systems. The funding covers the pilot but not the cost of running the system at steady state two years later.
Every institution deploying AI for the first time encounters these. The question is whether they encounter them having already paid for that knowledge, or whether someone else already paid for it. When Ethiopia built its agricultural advisory system in three months, it was not faster because it had more resources. It was faster because the deployment gaps Maharashtra had navigated at full cost were already mapped, with documented approaches to closing them, before Ethiopia's team started.
Deployment gaps are solvable. The knowledge of how to solve them exists, distributed across every institution that has completed a deployment. The problem is that this knowledge is not publicly accessible in a usable form. It lives in people's heads, in internal documents, and in conversations that only happen if the right meeting gets convened. Diffusion infrastructure is what changes that.
What is diffusion infrastructure?
Diffusion infrastructure is the system that makes pathway knowledge findable and usable at the moment a deployment team needs it. It has two components.
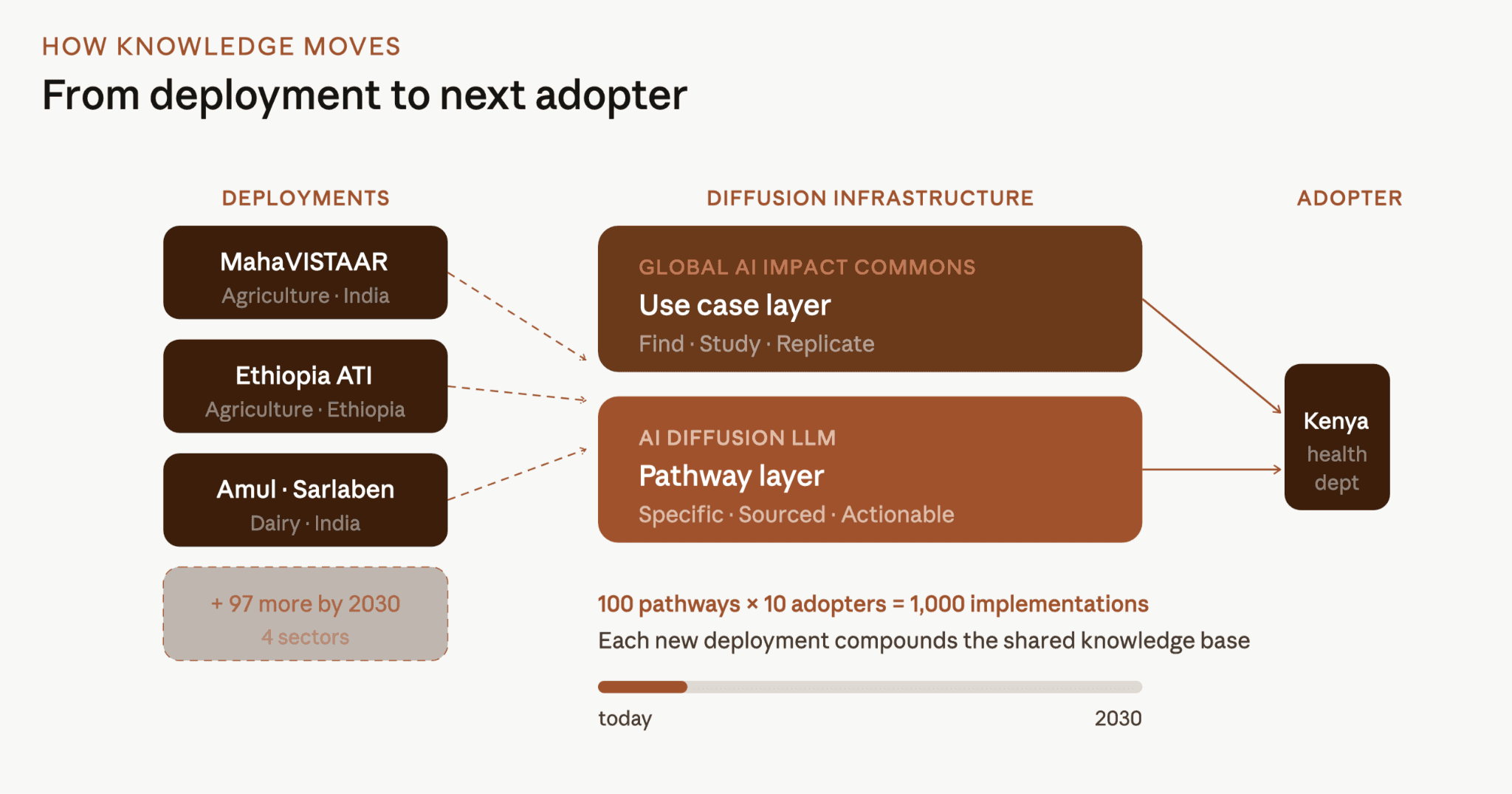
The first is the Global AI Impact Commons: a structured repository of use cases from real deployments across sectors and geographies. An institution scoping a deployment can find comparable cases, study what was built, and connect with the teams that built them. It is the reference library: complete deployments, catalogued and searchable.
The second is the AI Diffusion LLM: This operates on the pathway layer rather than the use case layer. It is built on the accumulated body of decomposed deployment decisions and is designed to answer the operational questions a deployment officer faces at the moment of decision.
A governance officer asking how to structure a data-sharing agreement between two state departments gets an answer drawn from the specific decisions three comparable deployments made, what each approach cost, and the conditions under which each one held.
Every answer is sourced and traceable to the specific deployment, institution, and people that produced it. This provenance is what makes the knowledge actionable for the institutions that need to use it.
Together, the Commons and the LLM address the two reasons deployment knowledge has historically failed to transfer. Use cases sitting in repositories go unread because they are too long and too specific to someone else's context.
Frameworks and best-practice guides get read but cannot be acted on because they are too general to answer the operational question in front of you. The Commons makes real deployments findable and studiable. The LLM makes the decisions inside them accessible at the level of specificity a deployer actually needs.
The 100 Diffusion Pathways initiative
In February 2026, eleven founding organisations committed to a shared target at the AI Impact Summit in New Delhi: 100 validated diffusion pathways by 2030, across agriculture, health, education, and livelihoods. Anthropic, Google Foundation, the Gates Foundation, UNDP, the governments of Ethiopia, Italy, and Kenya, Qhala, Carnegie India, the Observer Research Foundation, and EkStep Foundation share a common conclusion: AI that serves the people who need it most works better for everyone. Several pathways are already live. The New Delhi Declaration was signed by 89 countries.
100 pathways, each followed by ten organisations, produces 1,000 implementations. Each followed by a hundred, produces 10,000. The value compounds with every adopter that contributes back what they learned.
The goal, ultimately, is a farmer who becomes a better farmer. A health worker who makes better judgments. A teacher who teaches better. Not people made dependent on technology, but people with access to knowledge that was previously out of reach. The vocabulary in this piece exists to make that possible at scale, by ensuring that what one institution learns, the next one can use.
The knowledge commons is open. Whether you have a deployment to document, an expertise to contribute, a deployment you are planning, or funding to commit, reach out to david@peopleplus.ai and tell us where you fit.
